
置顶
未读
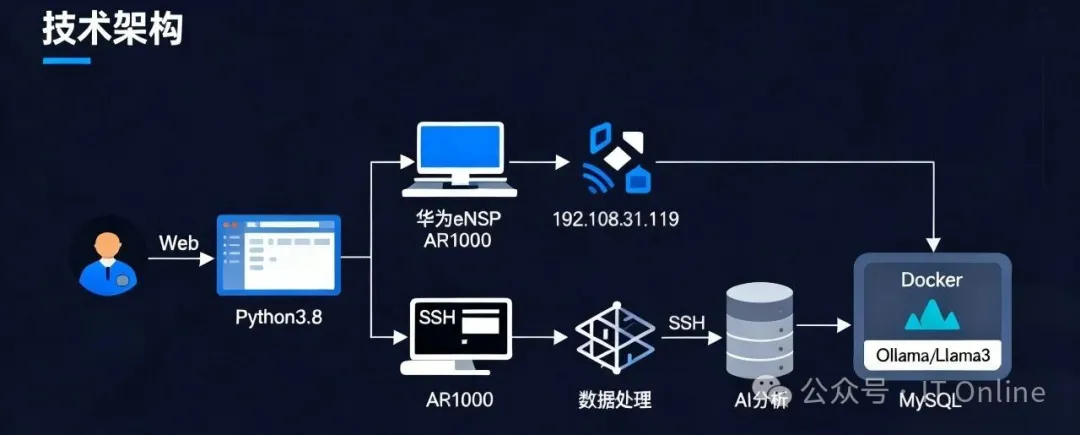
运维实验|部署本地Ai大模型巡检华为设备
上篇文章聊了,我们可以尝试用 AI 大模型重构网络巡检流程的思路,以及AI 大模型是如何落地网络自动化巡检的。今天呢我们就聊聊如何用 AI 大模型做些 “具体可落地” 的小尝试。 做运维的都知道,想试验新工具却怕影响生产环境?这次分享一个 “零风险低成本” 的实验:用 CentOS 8 系统,搭配华

Kubernetes + VMware vSphere 混合部署:企业级虚拟化环境搭建实战
摘要:随着云原生技术的快速发展,越来越多的企业希望在现有VMware vSphere虚拟化基础设施上平滑引入Kubernetes,实现传统应用与云原生应用的统一调度与管理。本文基于Kubernetes v1.28+ 与 vSphere 7.0 U3c/8.0+,采用外部云控制器(External C

等保 2.0 落地标杆实践:某省“国家级超算中心”安全防护体系全流程构建
(设备选型・策略配置・合规验收・运营优化) 一、项目背景与定级 作为某省核心科技基础设施与国家级超算算力枢纽,某省国家级超算中心承载科研计算、政务云服务、产业孵化三大核心业务,承担着支撑区域重大科研项目攻关(如航空航天模拟、生物医药研发)、政务数据集中处理(含民生服务、公共安全等敏感数据)、数字产业

从 0 到 1 搭建超算中心安全体系:超算中心等保 2.0 实践中的 5 个关键步骤
一、写在前面:为什么 “先合规、再运营” 是超算中心唯一可行的节奏 超算中心作为承载高性能计算、科研数据处理和关键业务运行的核心基础设施,天然属于三级及以上等保对象,未按规定完成备案即上线运行,将面临强制停机与高额罚款的严厉处罚;其服务的科研 / 工业用户往往携带敏感数据与

AI原生 · 全栈自治:企业级原生智能运维平台的架构革命
去年,一位在军工集团担任技术专家的师兄跟我倒了番苦水:“我们运维部监控着近万个指标,可故障真发生时,还是得联合多个部门几十名资深工程师,在海量日志里人工排查 2 小时” 结合现状细想,如今企业 IT 架构正朝着 “云 - 边 - 端 - 智” 全域融合的方向发展,数字孪生与工业互联网也深度交织,传统

2000元搞定企业级AI算力!DellR730XD+双P100+ESXi8.0+AlmaLinux9直通部署终极指南
导语:预算只有2000元,想搭能跑ResNet、BERT、YOLO的AI训练平台?别再交智商税了!我了解市场行情后,终于打磨出这套Dell R730XD+双Tesla P100部署方案——ESXi8.0虚拟化+AlmaLinux9直通(让虚拟机独占 GPU,性能不打折)双卡加速比1.8倍,按着步奏来

给特斯拉供货的 5 亿级零部件老板:18 个月落地全流程数字化,还要提前布局这 3 个未来风口
导语:“产值5亿,给特斯拉供货,在公司说一不二,但生产车间像‘黑箱’——订单到哪步了全靠问班组长;客户要追溯某个批次的质量问题,翻半天纸质记录才能答复;上游原材料断供预警总是滞后,临时调产又打乱全盘计划”——这是不是你每天要面对的糟心事? 更闹心的是:隔壁厂投3000万上智能设备,结果系统闲置、员工

《从 2 小时到 30 分钟!我用 Docker 重构了 ESXI 监控系统(含 Web 面板演示)》
在虚拟化部署中,ESXI 服务器的资源监控是运维核心需求。本文将带大家从零搭建一套轻量级 ESXI 监控系统,所有的组件和服务全部基于Docker 容器化部署,让大家能快速上手。 一、系统架构与核心功能 这套监控系统采用 "轻量化 + 容器化" 设计,避免传统监控工具的复杂配置,核心架构如下:ESX
